这篇文章将介绍如何搭建hadoop的开发环境,并且详细描述如何通过开发ide eclipse和intellij idea进行环境搭建开发hadoop的map-reduce程序。
程序准备:hadoop-2.6.0
开发环境搭建
eclipse开发环境搭建
在用eclipse搭建环境的时候,需要对不同版本的hadoop进行eclipse插件编译,有了该插件,我们可以创建hadoop project在创建一个hadoop project之后会默认引入我们需要的jar包,并且可以直接连接到hdfs上来监控hdsf的文件目录,在eclipse中搭建开发环境具体步骤如下:
1、编译hadoop-2.6.0 eclipse插件
【1】确保环境安装了ant,此处不给出安装方法
【2】下载hadoop-eclipse插件包,插件包下载地址:百度云网盘或者git thub
【3】解压插件包:执行
ant jar -Dversion=2.6.0 -Declipse.home=F:\tool\eclipse-jee-juno-SR2\eclipse-jee-juno-SR2 -Dhadoop.home=E:\hadoop\hadoop-2.6.0\hadoop-2.6.
【4】生成的插件在${hadoop2x-eclipse-plugin}/build/contrib/eclipse-plugin/目录中
2、eclipse hadoop配置
【1】 把插件包放到eclipse的plgun目录下
【2】重启eclipse配置,点击Window->Preferences->Hadoop map/reduce配置到下载hadoop -2.6.0.tar.gz包安装目录,作用是:创建Map/Reduce project的时候会自动根据该目录引入相对应的hadoop jar包,只有引入jar包之后,才能进行开发。配置好这一步后就可以开发M-R了。
【3】window->show view->other->Map/Reduce Locations,显示该视图之后,进入到该视图,新建一个location,并配置
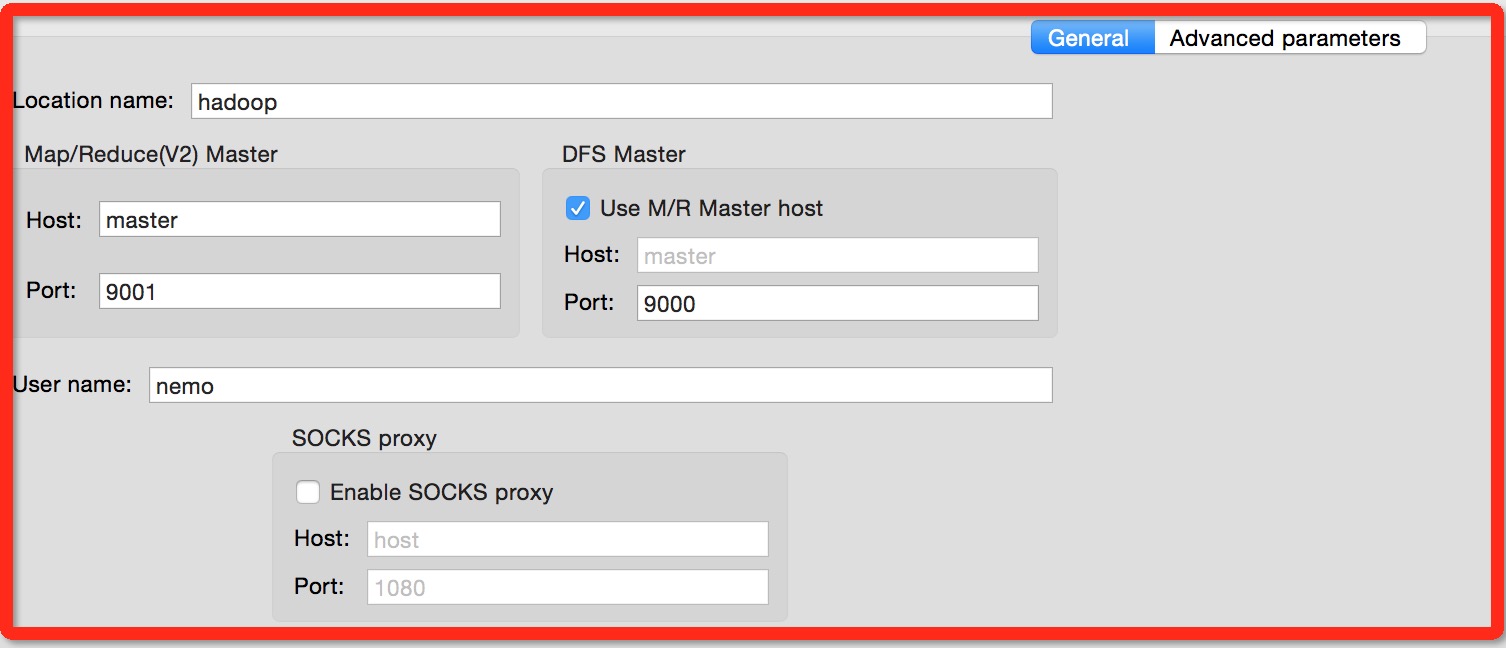
Map/Reduce Master: host:master post:9001
DFS master: host:master port:9000
user name:你的hadoop安装的用户名
#master为hadoop安装的core-site.xml中的ip地址
【4】配置好之后,在eclipse prokect视图会看到你配置的location,connet之后会看到hdfs上的的文件和目录。
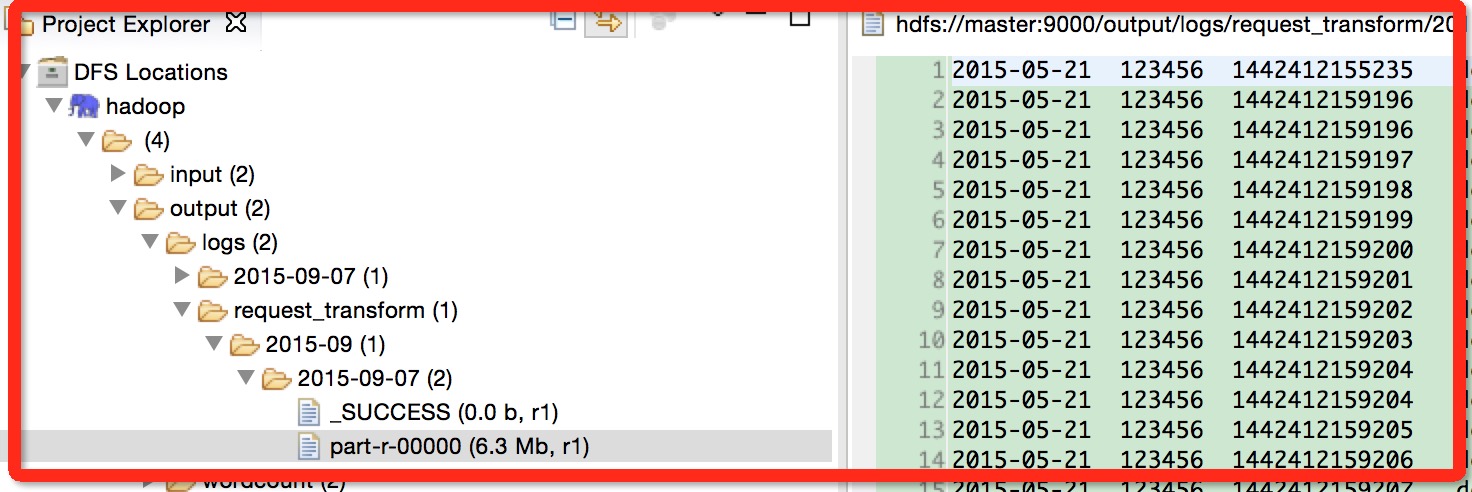
3、创建m-r project
接下来救可以创建Map/Reduce project了,编写一个hellp word,右键run hadoop就可以运行了。
intellij idea开发环境搭建
上面讲述了,如何利用eclipse搭建hadoop开发环境,那么intellij idea的开发环境怎么搭建呢。intellij idea是没有类似于eclipse的hadoop插件包的。上面已经说了,eclipse的插件包只是可以用来连接到hdfs文件系统,如果要开发M-R程序。只需要引入hadoop的har即可。那么接下来描述如何使用maven在intellij idea中搭建hadoop开发环境。
1、intellij idea创建maven项目这里就不多说了,先创建一个maven项目Test1。
2、配置pom.xml文件,补全pom.xml文件之后,idea会自动下载jar包并引入。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
3、创建WordCount实例小程序
package com.nemo.test;
import com.landray.behavior.base.util.HDFSUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static final String INPUT = "hdfs://master:9000/input/wordcount";
public static final String OUT_PUT = "hdfs://master:9000/output/wordcount";
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(INPUT));
FileOutputFormat.setOutputPath(job, new Path(OUT_PUT));
if (HDFSUtil.exits(conf, OUT_PUT)) {
System.out.println("改路径已经存在,先删除该目录......");
System.out.println("删除结果:" + HDFSUtil.deleteFile(conf, OUT_PUT));
}
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、本地提交:如果你的hadoop和idea在同一台服务器上,那么你可以选择Local提交
5、远程提交:如果你的hadoop是集群或者是其他服务器,idea在不同的服务器你可以选择远程提交,在hadoop-2.6.0中使用YARN进行调度。
本地提交
1、把coer-site.xml、log4j.properties复制到Test1项目的源码根目录下(保证编译后在class目录下能找到该两个文件),为什么要这样呢?因为你直接在idea中提交job,会加载class文件夹下的配置文件,如果没有log4j.properties文件,则会提示log4j没有初始化,结果是没有任务信息打印。core-site.xml一样,如果不放到源文件目录下,则会报hdfs权限等问题。
2、在idea中直接运行该类的猪方法,就可以提交到本地hadoop伪分布安装模式上了,可以对代码进行调试。
3、注意:我们在hadoop的配置文件mapred-site.xml指定了YARN调度,但是提交job的时候,根据debug之后发现,调用的是LocalCluster。并没有使用YARN.有如下两点原因:
【原因1:】需要把mared-site.xml文件和yarm.xml文件放到源码文件夹下
【原因2:】需要把文件程序打包才能进行远程提交job见:下一节远程提交
远程提交
idea远程提交
1、把core-site.xml、hdfs-site.xml、mapred-site.xml、yarn.xml、log4j.properties等文件放到源码根目录
2、先把该project进行打包
3、需要在程序代码中设置job.setJar
程序代码:
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("yarn.resourcemanager.address", "master"+":"+8032); //设置RM 访问位置
conf.set("mapreduce.jobhistory.address", "master:10020");
Job job = Job.getInstance(conf, "word count");
job.setJar("/Users/nemo/03ws/sp_intel/out/artifacts/hadoop_behavior_jar/hadoop_behavior.jar");
//job.setMapperClass(TokenizerMapper.class);
FileInputFormat.addInputPath(job, new Path(INPUT));
FileOutputFormat.setOutputPath(job, new Path(OUT_PUT));
if (HDFSUtil.exits(conf, OUT_PUT)) {
System.out.println("改路径已经存在,先删除该目录......");
System.out.println("删除结果:" + HDFSUtil.deleteFile(conf, OUT_PUT));
}
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、程序代码中:10020端口是hadoop历史服务,需要在服务器端启动
mr-jobhistory-daemon.sh start historyserver & #启动历史服务
5、在idea中运行程序,就提交了job,并且该种job提交方式还可以进行在idea中进行源码调试。
打包提交
1、使用maven或者idea的自动打包功能进行打包。
mvn package
idea自动打包:
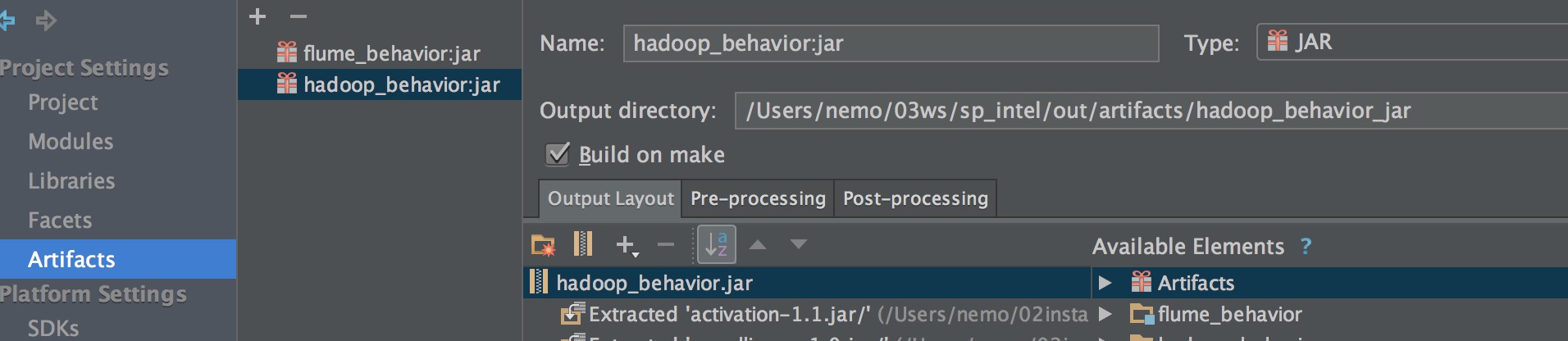
2、直接提交job到集群或者其他环境。
hadoop jar $home/03ws/sp_intel/out/artifacts/hadoop_behavior_jar/hadoop_behavior.jar com.landray.behavior.job.JobManager